Crédito da imagem: Image via Source article. Used under fair use for news commentary. · source
If you want to understand Nvidia's current position in the AI chip market, think about Intel in the early 2000s. Back then, if you wanted a high-performance x86 processor for servers, Intel was essentially your only option. AMD existed, sure, but the performance gap and ecosystem lock-in made switching impractical for most enterprise customers. Nvidia today occupies a similar position, but arguably with even stronger moats.
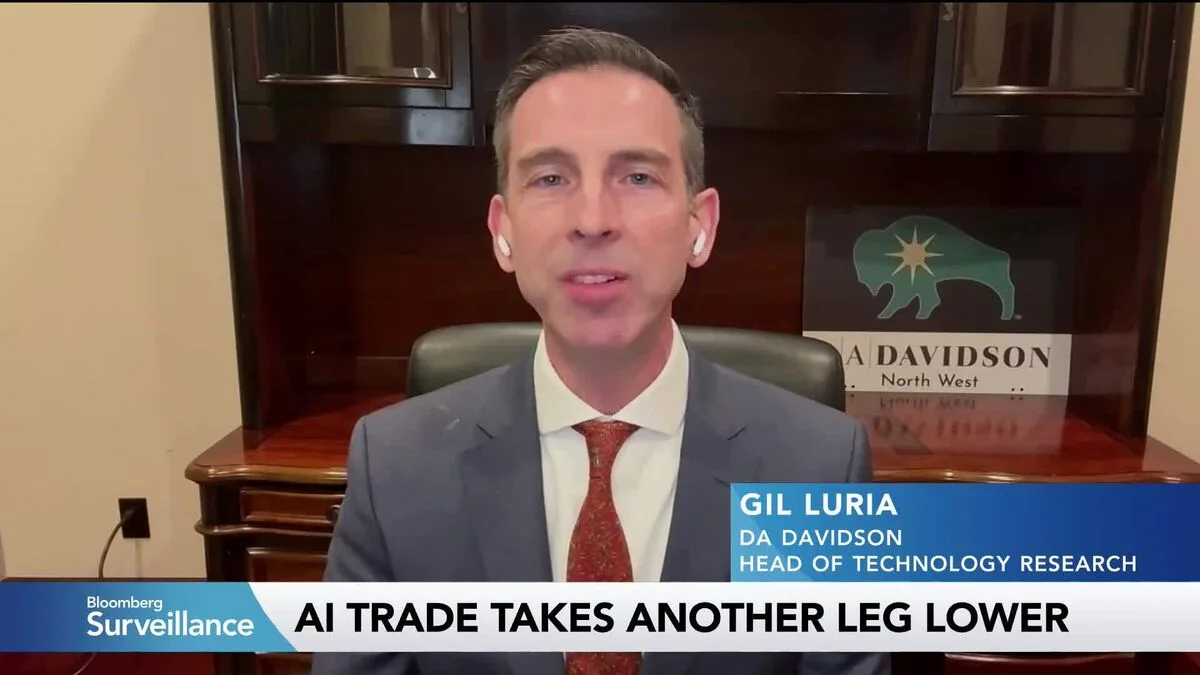
DA Davidson's head of technology research, Gil Luria, made this case explicitly on Bloomberg Surveillance this week, arguing that Nvidia's profit margins (currently hovering above 70%) are "relatively safe through the year 2030." The core claim: hyperscalers simply have no viable alternatives for the chips powering their AI data centers.
It's a bold prediction. And to be precise, it's worth unpacking what Luria is actually arguing and where the analysis might be incomplete.
The Bloomberg report summarizes the thesis succinctly: Nvidia's margins are protected because hyperscalers (think Google, Microsoft, Amazon, Meta) have few alternatives for AI training and inference workloads. This isn't just about raw chip performance. It's about the entire ecosystem: CUDA, the software stack, the tooling, the developer familiarity, the optimized libraries.
Cobertura relacionada
More in AI Models
A $30 billion cloud computing agreement isn't really about cloud computing. It's about something weirder.
Sarah Williams · 8 hours ago · 4 min
A new analyst forecast suggests hyperscalers have no real alternatives, but the reasoning deserves closer scrutiny.
Aisha Patel · 11 hours ago · 5 min
Morgan Stanley's CIO thinks the semiconductor rally is built on a misunderstanding, and honestly, I'm starting to wonder if she's right.
Sarah Williams · 12 hours ago · 4 min
Wealth managers are staring down an AI threat, and it's not humanoid robots — it's chatbots that clients actually trust.
Luria's timeline is specific. Through 2030. That's roughly four years from now, which in semiconductor terms is about two to three major product cycles. The implication is that even if competitors are developing alternatives today, they won't reach parity in time to meaningfully erode Nvidia's pricing power within that window.
I should note that the available reporting doesn't include detailed methodology or the specific competitive analysis underlying this conclusion. We're working with a summary of Luria's remarks, not a full research note. That matters for evaluating the strength of the claim.
Let me walk through the landscape as it currently stands, because the "no alternatives" framing deserves some scrutiny.
Custom silicon from hyperscalers themselves. Google has been deploying TPUs for years. Amazon has Trainium and Inferentia. Microsoft is developing Maia. Meta has its own MTIA chips. These aren't theoretical projects; they're shipping silicon running production workloads. The question is whether they can scale to replace Nvidia across the board, and here the answer is genuinely unclear.
The hyperscalers have been cagey about actual deployment numbers and performance comparisons. Google claims TPU v5p is competitive with H100 for certain workloads, but "competitive for certain workloads" is doing a lot of heavy lifting in that sentence. Training large language models at frontier scale still appears to favor Nvidia hardware, though this is based on inference from public statements rather than published benchmarks (I know I'm being picky here, but the absence of rigorous third-party comparisons is notable).
AMD's MI300 series. AMD has made genuine progress. The MI300X has respectable specs on paper, and several hyperscalers have announced purchases. But "announced purchases" and "deployed at scale as primary training infrastructure" are different things. The software ecosystem remains Nvidia's real moat. CUDA has decades of optimization, libraries, and developer familiarity. ROCm is improving but, actually, the research shows that porting complex ML workloads still involves meaningful friction.
Intel's Gaudi line. Intel acquired Habana Labs specifically for this market. Gaudi 3 is shipping. But Intel's track record on AI accelerators has been, to put it diplomatically, inconsistent. The company has pivoted strategies multiple times. It's too early to say whether Gaudi will achieve meaningful market share.
Startups. Cerebras, Groq, SambaNova, and others have interesting architectures. Some have landed significant contracts. But none have demonstrated they can compete at hyperscale for general-purpose AI training. They tend to target specific niches: inference optimization, sparse workloads, particular model architectures.
The strongest version of Luria's argument isn't that alternatives don't exist. It's that switching costs are prohibitive at the scale hyperscalers operate.
Consider what it means for Google to move a production workload from Nvidia to TPU. The ML engineers need to adapt their code. The training pipelines need modification. The debugging and profiling tools change. The performance characteristics shift in ways that require retuning hyperparameters. Multiply this across thousands of engineers and thousands of models, and the organizational cost becomes substantial.
Now consider that hyperscalers are simultaneously racing to train frontier models, deploy inference at scale, and ship products. The opportunity cost of diverting engineering resources to chip migration is real. If Nvidia hardware works and delivers predictable performance, there's a strong argument for just... continuing to use it, even at 70%+ margins.
This is the lock-in dynamic. It's not that alternatives are technically impossible. It's that the activation energy required to switch is high enough that it won't happen quickly, even if alternatives become cost-competitive.
The 2030 timeline assumes no discontinuities. Four years is a long time in AI. If there's a major architectural shift in how models are trained (and there are researchers exploring alternatives to transformers, though nothing has displaced them yet), the chip requirements could change in ways that open opportunities for competitors. This hasn't been replicated yet, but there's interesting work on neuromorphic approaches, analog computing, and optical processing that could matter on longer timescales.
Export controls are a wildcard. The US government has progressively tightened restrictions on AI chip exports to China. This affects Nvidia's total addressable market and could accelerate Chinese domestic chip development. How this plays out by 2030 is, genuinely, anyone's guess. The geopolitical situation remains fluid.
Margin sustainability isn't binary. Luria's claim is that margins above 70% are "safe." But there's a meaningful difference between 72% and 65%. Hyperscalers have negotiating leverage even if they can't fully switch away from Nvidia. They can credibly threaten to shift some workloads to alternatives, and use that leverage to extract better pricing. We don't know what volume discounts hyperscalers currently receive, and the reported 70%+ margins are company-wide averages.
The inference market is different from training. Training frontier models requires the absolute highest performance, which favors Nvidia. But inference (running trained models to serve users) has different economics. Inference workloads can often tolerate different performance/cost tradeoffs. This is where custom silicon and competitors have the strongest case. If a hyperscaler can serve inference 30% cheaper on custom chips, even with some performance penalty, the economics might favor migration for that specific workload.
If I were evaluating this claim rigorously (and I realize I'm being somewhat pedantic here, but this is how I think about these things), I'd want to see:
Actual deployment data from hyperscalers. What percentage of their AI compute is running on Nvidia versus alternatives? This data isn't public, and the hyperscalers have incentives to be vague. But it would tell us whether the "no alternatives" framing matches reality.
Total cost of ownership comparisons. Not just chip prices, but power consumption, cooling requirements, software development costs, and engineering time. Nvidia might win on raw performance but lose on TCO for specific workloads.
Roadmap analysis. What does AMD's MI400 look like? What's Google's TPU v6 architecture? How quickly is the gap closing, if at all? Luria's 2030 timeline implicitly assumes the competitive gap doesn't close dramatically in the next few product generations.
Software ecosystem trends. Is CUDA's dominance actually eroding? Are ML frameworks becoming more hardware-agnostic? PyTorch and JAX both support multiple backends, but in practice, how much friction is there?
Luria's core claim, that Nvidia's margins are protected through 2030, is plausible but not certain. The switching cost argument is strong. The ecosystem lock-in is real. And the competitive alternatives, while improving, haven't demonstrated they can match Nvidia at scale for general-purpose AI workloads.
But "relatively safe" is doing meaningful work in that sentence. It's not the same as "guaranteed." The analysis depends on assumptions about competitive progress, hyperscaler strategy, and market structure that could shift.
What I'd want to see next: a more granular breakdown of which specific workloads and customers are most vulnerable to competitive displacement, and which represent durable Nvidia advantages. The aggregate margin number obscures important variation underneath.
For now, the prudent interpretation is that Nvidia's position is strong but not impregnable. The company has execution risk on its roadmap (Blackwell and beyond), competitive risk from determined and well-resourced challengers, and regulatory risk from export controls. Whether 70%+ margins survive through 2030 depends on how all of these factors evolve.
We don't know yet. And anyone who claims certainty in either direction is probably overconfident.